Spotlight: Evaluating MongoDB Atlas Vector Search
News Flash: Vector databases and vector searches are no longer a differentiation. Yes, how fast times change as what was cool just six months ago is suddenly table stakes!
What is cool is a unified ecosystem that supports generative AI use cases on the same stack that supports traditional OLTP and OLAP use cases. In other words, it avoids organizations having to maintain separate stacks for structured data and unstructured, for batch and streaming, and for transactional and analytical. It also puts them on the road to a simplified cost-effective data infrastructure that is easy to manage and grow. On top of that, it provides iron-clad data security and governance across a hybrid multi cloud deployment footprint.
MongoDB has been a frontrunner in the non relational databases with over 45,000 customers. Like many other vendors, they too announced their generative AI capabilities in the summer of 2023. However, as its customers moved faster than expected to leverage these capabilities, MongoDB accelerated its own development and went GA with its Atlas Vector Search on Dec 4, 2023.
This document evaluates MongoDB Vector Search against the author’s own Vector Database Evaluation Criteria.
Introduction
What stands out in MongoDB’s new offering is its name, Atlas Vector Search. You’ll notice that it’s not called a vector database, which is a smart move because vector storage is the means to build and deploy gen AI apps and not a destination itself. So, while MongoDB stays true to its roots as a developer platform by providing both of these capabilities,, it chose to name its offering after the end goal; Vector Search.
MongoDB is also making a distinction that developing Gen AI apps is no longer a task relegated to the hard-to-find data scientists, but rather it has been “shifted left” into the domains. The concept of shift left has gained traction for data teams all year long. Yours truly wrote about it in the context of data security, quality, and observability. Now, it is being applied to AI as well.
For a recap, here is the evaluation criteria:
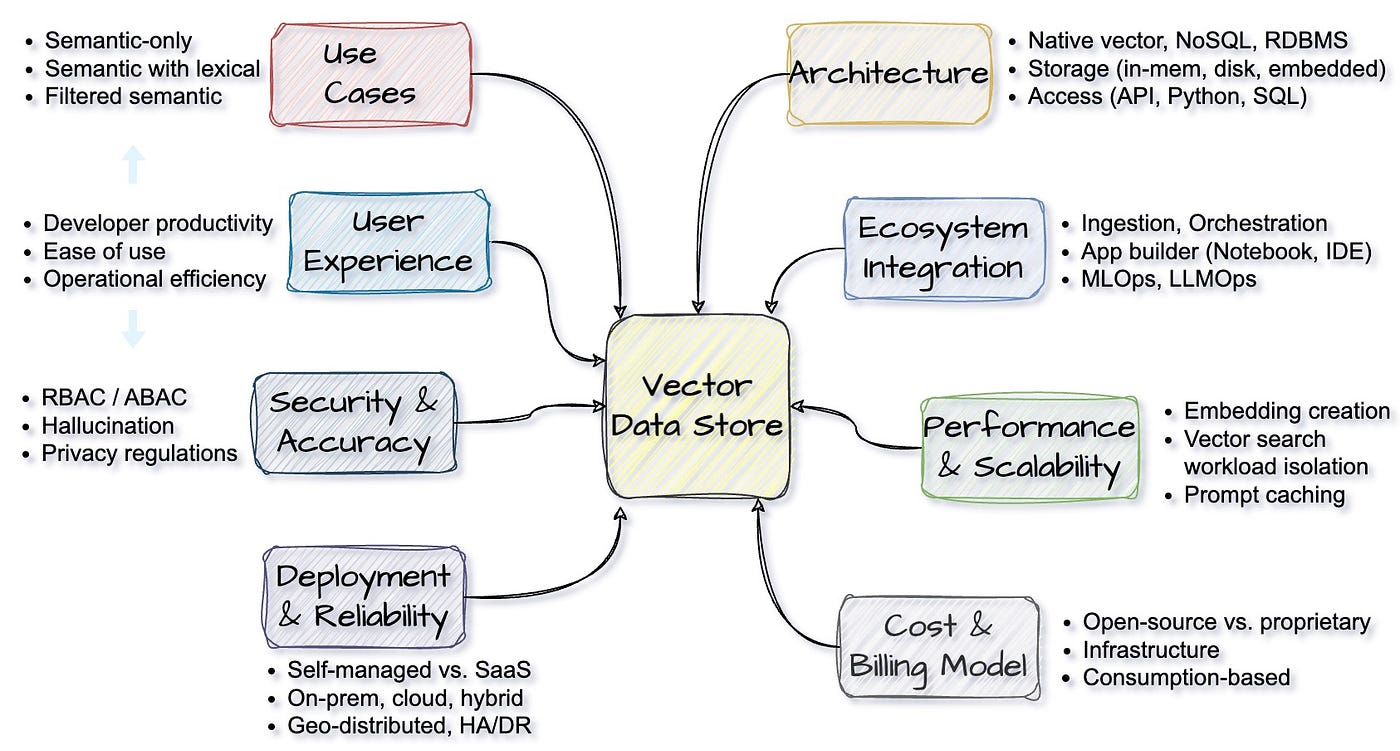
As the vector search capability is built as an extension to its time-tested underlying database, it leverages many of the benefits inherent in the underlying system. We will evaluate each criteria next.
Use Cases
MongoDB combines lexical and semantic searches in the same query API call, because the vector embeddings for its attributes are stored within the document. Atlas Vector Search augments existing Lucene-based Atlas Search via a single query and a single driver client-side, so it reduces dependencies for developers. Vector Search also provides additional context to LLMs to reduce hallucinations and brings in private data at inference time.
Like full-text search, Vector Search is now available in Atlas, alongside capabilities like transactional processing, time series analytics, and geospatial queries. This enables business use cases such as recommendation & relevance scoring, feature extraction, image search, Q&A systems and, of course, chatbots, etc.
MongoDB Atlas Vector Search powers the well-known retrieval augmented generation (RAG) pattern. According to this pattern, the vector store is first used to filter and create a relevant context using search indexes based on approximate nearest neighbor (ANN) libraries before sending a prompt to an LLM to fulfill users’ requests. This process addresses the limitation of LLMs that have a limited context window. Also, by pre-filtering, user requests are more tightly bound which reduces latency, cost, and improves the quality of generated output. How good the quality of prompt is goes a long way in reducing LLM hallucinations. The new $vectorSearch aggregation stage is also used in an MQL statement to pre-filter documents.
Architecture
Standalone vector databases have arisen in recent years to store embeddings for primarily unstructured data so that similarity searches can be performed on them. This ability unlocks deep intelligence from text, PDFs, images, videos, etc. However, they need to integrate with other enterprise databases that have existing corporate data to deliver deeper insights.
MongoDB adds vector embeddings as an attribute inside its documents, which are stored natively inside your BSON documents using arrays. This allows MongoDB to store embeddings for all structured and unstructured content, alongside the enterprise data.
The embeddings are created using an embedding model, like OpenAI’s text-embedding-ada-002, Google textembedding-gecko@001, etc. MongoDB Atlas then indexes the embeddings using HNSW to provide an ANN vector search.
With the introduction of Atlas Search Nodes, users can now scale their memory-intensive vector search workload independently from their transactional workload. The indexes live on the new Search Nodes and can be scaled independently from the transactional cluster infrastructure. This separation helps provide better performance and high availability.
Ecosystem Integration
Gen AI is a hotbed of new companies and approaches. Consequently, one very important evaluation criteria is how well a database vendor’s vector capabilities are integrated into this ever-expanding ecosystem of model providers as well as ISVs developing the integration, chaining, and operations mechanism.
MongoDB Atlas Vector Search is able to use embedding models from OpenAI, Cohere and open-source ones deployed at Hugging Face. LangChain, LlamaIndex, and Microsoft’s Semantic Kernel have arisen as important players that help glue together many of the moving parts of RAG. MongoDB has integrations with all of them.
Performance & Scalability
In the high dimensional vector space, ANN techniques like HNSW compare embeddings pertaining to user requests against stored embeddings to find a specified number of the nearest neighbors. MongoDB has added tuning parameters called, “numCandidates” and “limit” to tune the accuracy of the ANN algorithm.
MongoDB Atlas clusters can scale vertically by adjusting the tier of the cluster as well as horizontally through the use of sharding. Furthermore, with the introduction of Search Nodes, customers can even decouple their Search and Vector Search workloads from their database workloads to scale them independently. Lastly, Atlas clusters are available in any of the major hyperscalers: AWS, Azure, and GCP.
Cost and Billing Model
Organizations are keen to contain the overall cost of the data ecosystem, in other words, the total cost of ownership (TCO). A multi-function data developer system that is enhanced by vector search avoids the cost of procuring and integrating specialized and disparate solutions. It also improves consistency of the data pipeline and lowers the cost of debugging and maintenance.
Also, Vector Search is supported directly on top of the cluster and consumes resources in the same way that your cluster consumes resources, meaning no additional billing model is needed.
Deployment & Reliability
MongoDB Atlas Vector Search leverages the underlying managed platform’s automatic patching, upgrades, scaling, security, and disaster recovery capabilities. Additionally, Atlas’ high availability (HA) and automatic failover are multi cloud, multi region and multi zone.
Deployment automation (CI/CD) is supported through partners like HashiCorp and AWS CDK.
Security & Accuracy
Atlas Vector Search inherits MongoDB’s security credentials. By avoiding movement of data from a corporate database to a separate vector database, unnecessary security tasks can be avoided as well. Also, MongoDB extends its transactional consistency for operational workloads into the vector space by leveraging the metadata in creation of embeddings. This, in turn, helps reduce hallucinations.
Fine grained access control, separation of duties, encryption, auditing, and forensic logs are some of the capabilities that Vector Search inherits from the underlying system. Additionally, you can take advantage of core Atlas capabilities like Queryable Encryption alongside your Vector Search workloads to prevent the inadvertent leakage of sensitive data such as personally identifiable information(PII) into model training or inference.
User Experience
MongoDB’s unified query API across services — ranging from CRUD operations on transactional data to time series to vector search — helps improve developer productivity by avoiding potential context switching that would be incurred if each service was offered by disparate databases, query languages and drivers.
By virtue of Atlas’ managed services, the vector search leverages the ease of use of the existing document database. This makes it easy to build, deploy and maintain apps.
In addition, developers can test Gen AI applications locally with the Atlas CLI using their favorite IDE like VSCode or IntelliJ etc. before deploying them in the cloud.
Summary
MongoDB’s vector search capability is not a separate SKU. The figure below shows how it extends the overall scope of MongoDB Atlas.
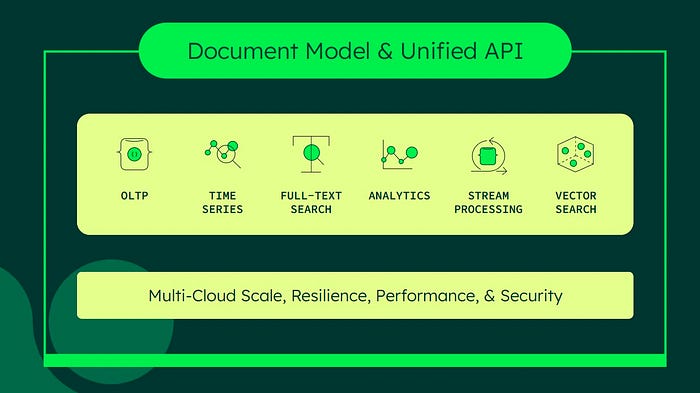
RAG is a useful way of asking large language models to generate responses but use only your proprietary data instead of public data that was used to train the models. MongoDB Vector Search allows RAG architectures to utilize semantic search to bring back relevant context for user queries to reduce hallucinations, bring in real-time private company data, and remove the training gap where the LLM is out of date.
Although, in its November 2023’s announcement, OpenAI refreshed GPT-4’s training corpus from September 2021 to April 2023, organizations still want to be able to leverage their most current data. MongoDB Vector Search provides the platform to develop and deploy generative AI applications on most up-to-date corporate data. MongoDB lists its vector search capability as being used for conversational AI with chatbots and voicebots, co-pilots, threat intelligence and cybersecurity, contract management, question-and-answers, healthcare compliance and treatment assistants, content discovery and monetization, and video and audio generation.
