FAQ on Demystifying AI Agents
Is an AI agent a groundbreaking leap in the evolution of technology, or is it just the latest buzzword in the ever-accelerating hype cycle of generative AI? In a world captivated by the promise of artificial intelligence, terms like “agent,” “assistant,” and “copilot” have become pervasive, sparking both excitement and skepticism. Are we on the cusp of an era where agents fundamentally reshape industries and workflows, or are we witnessing another fleeting fascination destined to fade as we pivot to the next shiny object?
This blog delves into the core of the AI agent phenomenon, as we tackle several key questions that are shaping conversations around this technology, including:
- What exactly is an AI agent?
- What are the different types of AI agents?
- What is the LLM application space (chatbots, assistants, copilots, and agents)?
- How to build an AI agent (lifecycle)?
- What are the components of an AI agent stack (architecture)?
- What is an AI agent framework?
- What lessons have we already learned (and what pitfalls should we avoid)?
Many additional questions will be addressed in future articles. Among the most frequently asked are:
- Is now the right time to invest in agentic AI?
- How much of our existing investment (including skills) can be leveraged?
- Who has successfully implemented AI agents?
- How will improvements in LLMs’ reasoning capabilities impact agentic use cases in 2025?
- How should one get started?
Although the concept of AI agents is still in its formative stages, organizations must start laying the groundwork now to stay ahead. This blog seeks to demystify the foundational ideas driving this emerging space, providing clarity and direction.
If you prefer a video format of this blog, you can watch it here.
1. What is an AI Agent?
At its core, an agent is a program designed to automate tasks and operations for humans and organizations. Think of it as a specialized digital twin — only smarter. Its key innovation lies in leveraging foundation models to make automation both contextually aware and autonomous.
While automation itself isn’t new, Robotic Process Automation (RPA) has enhanced productivity for decades, but AI agents go beyond rigid rule-based systems. They tackle cognitive tasks requiring high-level thinking, reasoning, and problem-solving, powered by generative AI. This enables them to work with unstructured data like documents, videos, images, and audio.
For instance, a customer service AI agent can analyze an incoming call recording to understand its content and context. Based on this understanding, the agent can take appropriate actions, such as resolving issues, escalating to the right team, or providing instant feedback. This not only reduces manual effort but also enhances customer satisfaction by enabling timely and accurate responses.
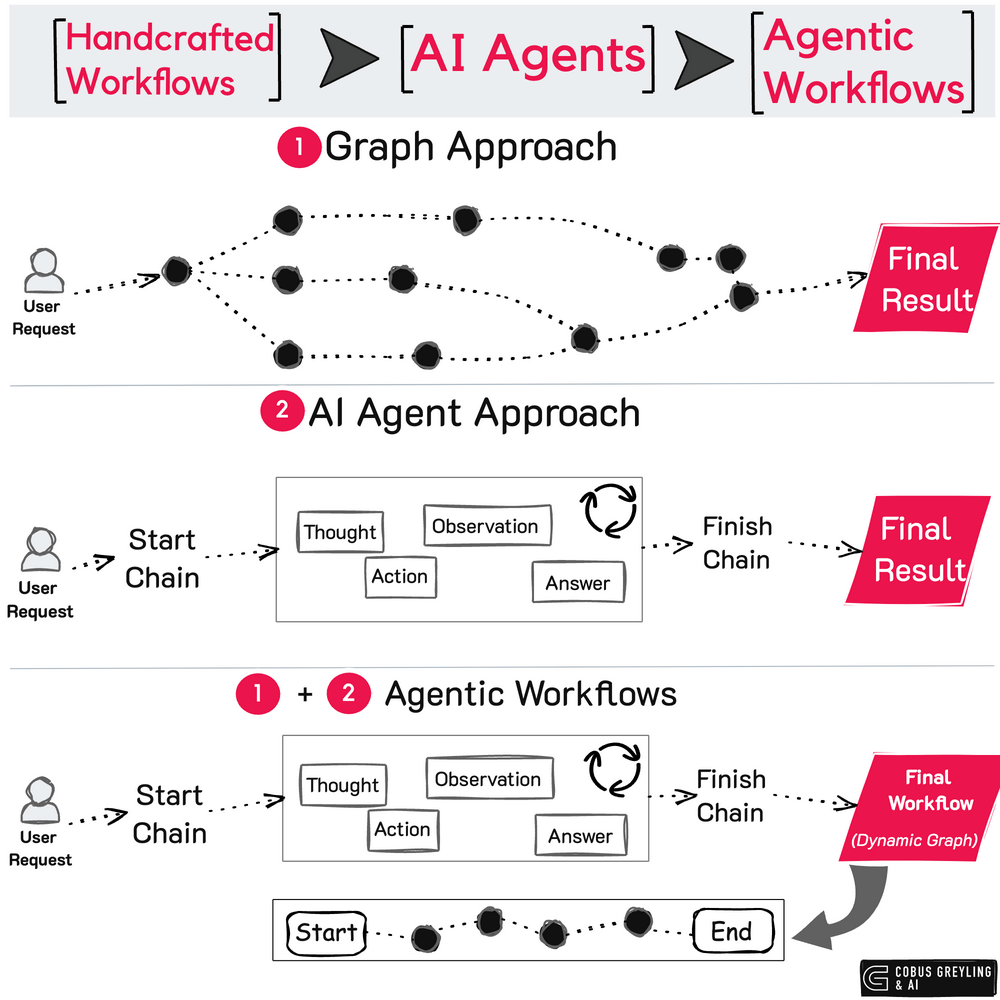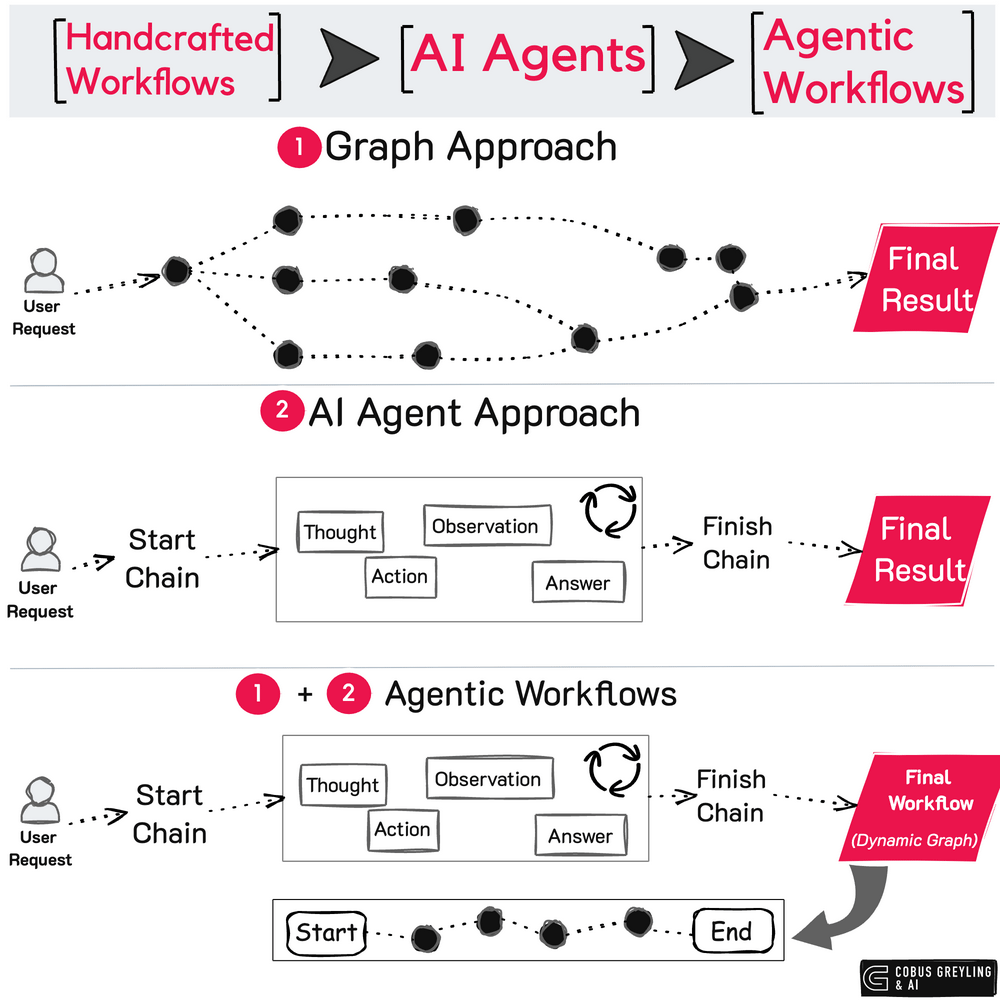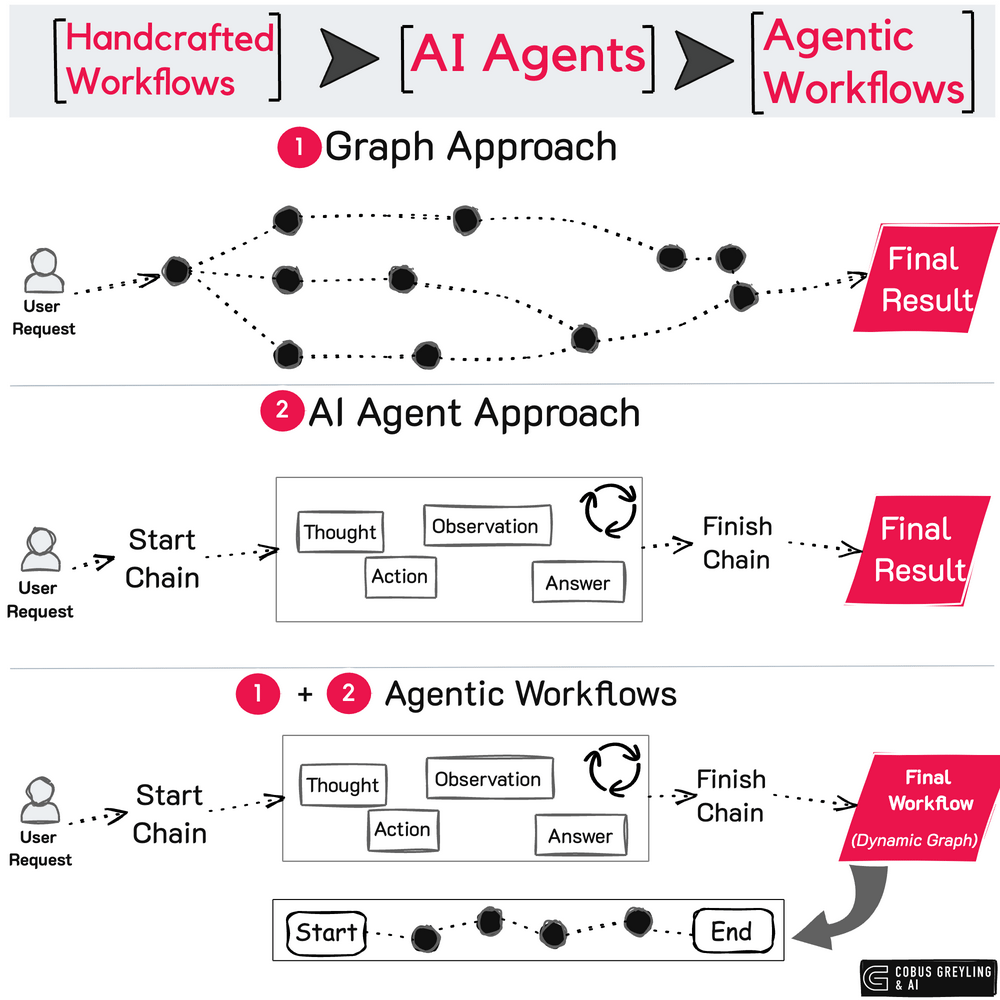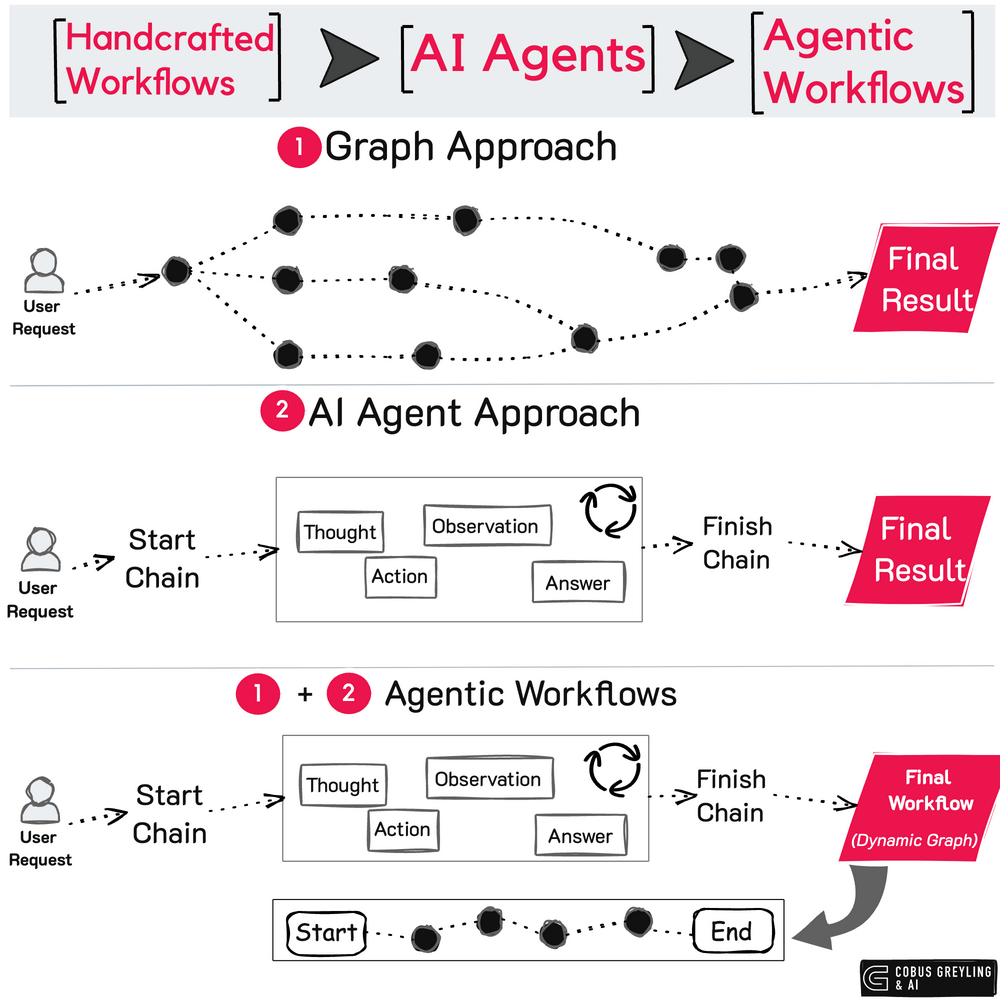
How AI agents work
Agents go through a multi-step process as shown in Figure 1.
- Sense: Agents perceive and interpret their environment to determine desired outcomes. For instance, an agent might detect a new email from a prospect requesting information or scheduling a demo. In this scenario, the “environment” is the email client, such as Microsoft Outlook, and the agent could function as a digital twin of a Sales Development Representative (SDR). This enables the agent to process and respond intelligently, replicating the role of an SDR in automating key tasks and streamlining workflows.
- Reason: At this stage, the agent interprets the desired objective. It then breaks this objective down into granular tasks required to achieve it. This process is powered by a Large Language Model (LLM) with advanced reasoning capabilities, such as OpenAI’s O1. The LLM employs techniques like chain-of-thought reasoning, reason-act (ReAct), and few-shot learning to systematically decompose the objective into actionable subtasks. This structured approach enables the agent to effectively navigate complex tasks.
- Plan: Agents devise a strategy for executing tasks and initiating necessary actions. For example, a Sales Development Representative (SDR) agent tasked with rescheduling a prospect meeting might create a “multi-step” plan: update the meeting time, send an email confirming the rescheduled appointment, and notify the team of the changes. For each subtask, the agent identifies the most efficient and effective method to achieve the objective, ensuring precision and alignment with overall goals.
- Act: Finally, agents orchestrate workflows by seamlessly connecting to appropriate systems of record. Leveraging paradigms such as Retrieval-Augmented Generation (RAG) and function-call integrations, they ensure security and governance compliance while executing subtasks. They utilize short-term memory for active sessions and tap into external applications for long-term memory, such as retrieving a customer’s preferences or purchase history stored in a database management system. This integration empowers agents to deliver context-aware, personalized, and efficient outcomes.
Agents emulate real-life workflows and are applicable across industries, from booking flights to processing bank transactions. They interact seamlessly with existing systems and escalate issues to human intervention when necessary. The future envisions a world where every individual has access to a personal AI assistant or agent tailored to their unique needs. These assistants could help students with homework or exam preparation and serve as travel planners. Such AI agents aim to enhance daily life by providing intelligent, personalized support across various roles and activities. The future of ERP may involve AI agents, which could potentially disrupt traditional monolithic systems.
Despite some skepticism, AI agents are rapidly gaining traction. LangChain’s State of AI Agents survey of 1,300 respondents revealed that over 50% of companies already have agents in production, while nearly 80% are developing them.
The devil is in the details; hence, the obvious question is: how does one build or deploy these agents? Before we get to that question, we need to further understand that agents come in various forms.
2. Types of AI Agents
At Microsoft’s Ignite conference in November 2024, the company highlighted the integration of AI agents across its product portfolio, including SharePoint, Teams, and Microsoft 365. These agents abstract the complexity of underlying models, making them as intuitive to create as a PowerPoint presentation. Microsoft categorizes agents into four types: Personal, Organizational, Business Process, and Cross-Organizational.
Figure 2 presents a 2x2 matrix that offers another perspective on categorizing different types of agents, based on their functionality and scope boundaries. This approach helps clarify how agents can vary in terms of their roles and the extent of tasks they handle, from highly specialized agents with a narrow scope to more versatile agents that manage a broader range of activities.
- Task:
Focus on discrete, well-defined single-purpose tasks. Proper scoping ensures deterministic outputs and repeatability. Their goal is to improve personal productivity by handling time-consuming tasks. These are also called “narrow agents” as they excel in their designated areas but lack the ability to generalize their knowledge or skills to other unrelated tasks.
Examples: travel booking assistants, research and summarization copilots.
Task agents can be categorized as either “narrow” or “broad” based on their range of capabilities. Narrow task agents are specialized, designed to perform specific functions or solve particular problems, whereas broad task agents are more versatile, capable of handling a wide variety of tasks and adapting to different situations. The next example illustrates a broad task agent, showcasing its flexibility and ability to manage multiple responsibilities within diverse contexts.
- Process:
Designed to manage end-to-end workflows tailored to specific domains such as supply chain, customer service, healthcare diagnostics, finance, or retail. This type of agent is also called a domain-specific agent.
In Figure 2, the example illustrates a fraud detection agent that performs a series of tasks, including detecting anomalies, conducting root cause analysis, remediating the issue, raising alerts, and sending notifications. This agent seamlessly chains multiple functions together, demonstrating its ability to handle complex workflows autonomously, ensuring timely responses and thorough action within the fraud detection process.
Examples: Drug discovery agents, recommendation engines, and customer segmentation tools.
- Role:
Targeted at role-specific functions supporting defined tasks, such as data engineers, DevOps professionals, or project managers. They can assist with code generation or help solve data transformation and quality tasks.
Role agents can also be broad or narrow depending upon their scope.
Examples: SDR agents, customer success copilots, supply chain assistants, financial advisor agents.
There are several ways of classifying different types of agents, based on various factors:
- Learning approach: reflex based on current inputs, goal-based agents work towards specific objectives, utility-based are optimized for maximum value, model-based use internal models to make decisions, while learning agents improve performance through experience.
- Environment interaction: reflex agents respond to the current input only, temporal consider how actions unfold over time, episodic handle each event independently, sequential consider past experiences and future actions
- Architecture: neural network-based, rule-based, logic-based, probabilistic
- Autonomy level: supervised agents work under human control, while semi-autonomous require some human oversight, and fully autonomous operate independently.
Understanding the types of AI agents is crucial because it enables organizations and developers to align the agent’s purpose with the most suitable foundational models, tools, and infrastructure. This alignment can significantly impact the agent’s success and cost efficiency. Moreover, identifying the required features — such as reasoning capabilities, adaptability, or real-time responsiveness — ensures that each agent type is optimized to meet its specific functional and performance needs effectively.
3. LLM Application Ecosystem
This section aims to clarify the various terms commonly used today, such as chatbots, assistants, and copilots, which are often used interchangeably.
The categorization of LLM applications reflects the nature of the task, degree of complexity, as well as the level of automation of the task.
- Retrieval Augmented Generation (RAG)
RAG systems combine the generative power of LLMs with external knowledge sources to produce more accurate and contextually relevant outputs. These systems are essential for building AI-powered search engines, knowledge base query systems, and document summarization tools.
- Chatbots
Chatbots are essentially wrappers around an LLM’s completion API. They assist with tasks such as writing code, summarizing documents, and predicting the next word, all based on training with vast amounts of data.
These LLM applications assist users in real-time by providing suggestions, answering questions, or guiding through processes.
- Co-pilots and assistants
These systems offer more advanced integration capabilities with “actions” and tools. For example, they often integrate with platforms like IDEs, customer service interfaces, and personal productivity tools. In addition to fulfilling the basic requirements of AI chatbots, these assistants provide more seamless tool integration, where LLM inference can trigger specific actions. They typically collaborate with users to help accomplish tasks more efficiently.
Examples include coding assistants, customer support bots, and personal assistants like AI-driven calendar managers.
- Semi autonomous agents with human-in-the-loop
These applications involve LLMs operating with a degree of autonomy while still requiring human oversight or intervention. The human-in-the-loop aspect is crucial for ensuring accuracy, safety, and ethical considerations, especially in sensitive or high-stakes environments.
Examples include content moderation systems, decision support systems in healthcare, and AI-driven project management tools, where human approval is necessary for critical decisions.
- Autonomous agents
This category includes LLM applications that operate independently with minimal or no human intervention. These agents can perform tasks, make decisions, and execute actions based on their programming and the data they process. Autonomous agents adapt to dynamic environments and learn from interactions.
Examples include self-driving vehicle AI, automated incident response agent, AI Telecaller, AI data analyst agent.
Now that we have explored agents and other applications in the LLM applications ecosystem, it is time to change tracks and start diving into building and deploying agents.
4. Agent Development Lifecycle (ADLC)
When SaaS first emerged, it was humorously dubbed “just a wrapper around MySQL with added user experience and workflows.” Since then, the SaaS industry has exploded, with over 17,000 companies in the field and more than 300 achieving unicorn status. In a similar vein, startups leveraging foundation models began as basic wrappers around LLMs, but have evolved rapidly into more sophisticated solutions. This growth has catalyzed the emergence of a thriving AI agent ecosystem, signaling a potential transformation in the tech landscape.
As the value shifts from LLMs to the layers built on top of them, major players like Microsoft and Salesforce are reporting significant increases in the number of organizations leveraging their platforms to build and deploy AI agents. Figure 3 illustrates a structured approach to harnessing the power of these agents.
Let’s take a closer look at each step in the process.
Use case planning
Scoping the agent, prioritizing, and categorizing are essential initial steps in developing generative AI solutions that align with business objectives, operate cost-effectively, and deliver measurable value. Examples include enhancing customer service, boosting developer productivity by automating repetitive tasks, or improving decision-making processes.
In addition to business requirements, it is critical to identify non-functional requirements such as scalability, performance, ethical and bias considerations, security and access control, reliability, debuggability, and observability.
A practical strategy is to narrow the scope of the AI agent to reduce complexity while maintaining autonomy. Start small by breaking a complex process into well-defined, granular sub-tasks, ensuring a high degree of confidence in achieving each.
Agent system design and architecture
LLMs function as both language processors and intelligence layers. For instance, an LLM can interpret instructions to write a piece of code effectively. In an agentic architecture, however, the capabilities extend further: the same LLM can generate unit test cases, critically reflect on the outcomes, and iteratively refine the original code using the feedback.
These stochastic models excel at a variety of language tasks, such as understanding, extraction, and summarization. However, they may struggle with more complex tasks that require reasoning, math, planning, or consistency, making them unreliable and non-deterministic in those areas.
While agent systems are more flexible and creative in utilizing natural language compared to traditional software systems, they still borrow key design principles from both software engineering and machine learning. For example, agent systems often incorporate databases paired with REST/API interfaces to support end-user applications, whether on web, mobile, or native platforms. They also utilize ML principles such as model fine-tuning, hyperparameter adjustments, and parameter optimization, ensuring that agents are tailored to specific use cases and contexts.
Figure 4 provides a deeper view of the agent system design process.
As shown in the figure, agents combine core principles from software engineering, such as error handling and reliability, with optimization techniques from machine learning. Beyond these foundational elements, agent systems introduce additional layers that enable autonomy, planning, memory, and the ability to sense and interface with external environments. These added capabilities allow agents to act more dynamically and efficiently, making them adaptable to a wide range of real-world scenarios.
Agent evaluation and testing
Evaluating models has long been a key task in AI development, leading to the creation of several open-source benchmarks like MMLU, GPQA, and MATH. However, when it comes to evaluating agents, the process becomes more complex. Agents must be tested to ensure they meet desired outcomes with reliability and safety. But unlike typical benchmarks, task or question boundaries in agent evaluation are often highly specific to the agent’s domain, making it challenging to develop universal evaluation methods. Standard evaluations may fail to capture real-world tasks or unforeseen scenarios that agents may encounter.
Additionally, the environments in which agents operate are dynamic and difficult to recreate accurately. This further complicates the task of agent evaluation. Evaluating an agent’s reasoning and planning capabilities is crucial, particularly for agents tasked with managing complex, multi-step processes. Traditional testing methodologies need to be adapted to account for the stochastic and probabilistic nature of agent outputs.
While conventional software testing tends to focus on quantitative metrics, agent evaluations require a blend of quantitative and qualitative methods to fully assess their performance. Figure 5 outlines an agent evaluation framework that integrates these principles.
Let’s look at each function in detail.
- Test case development
Start by establishing a standardized environment for agent evaluation. For example, to evaluate a data analyst agent, ensure access to the relevant databases, SQL query engines, and reports or dashboards. Clearly define the capabilities of your specific agent use case and identify the key performance indicators (KPIs) that matter to both the user and the business.
Next, identify the relevant tasks and subtasks that the agent will perform, allowing you to create a distribution of evaluations covering these various components. Define a set of tests that assess the agent’s multi-step reasoning capabilities. These tests should include scenarios that introduce uncertainty to the agent’s reasoning, allowing you to evaluate how the agent behaves under such conditions.
For each of these tests, compare the agent’s performance with a human baseline to evaluate how well it handles complex reasoning tasks. Finally, define KPIs based on these tests, allowing for a quantitative assessment of the agent’s reasoning and decision-making abilities.
- Evaluation criteria
Identifying the right distribution of test cases across both functional and non-functional requirements is crucial for successfully deploying agents into production. It is essential to evaluate the agent across a wide range of functionalities. For example, assess tool usage efficiency, model-specific outcomes, and multi-turn outputs. Additionally, incorporate tests that evaluate the agent’s handling of bias, security measures, and safeguards. You should also test the agent’s ability to process multiple parallel requests and handle asynchronous responses effectively. Establish detailed performance metrics, including response times, task completion rates, and decision-making precision.
Quantitative evaluation of an agent, such as a data analyst agent, may involve comparing the output of similar SQL queries run manually versus by the agent. These evaluations are relatively straightforward. However, for more complex tasks — such as when a research agent summarizes academic papers — qualitative evaluation becomes necessary. In such cases, the quality of the generated text must be assessed for accuracy, completeness, and depth.
Qualitative assessments of LLM/agent output have led to the development of various scoring strategies. These can be broadly categorized into pass/fail evaluations (accuracy), text attribute scoring (sentiment, similarity, politeness), readability assessments (e.g., ARI grading), summarization (e.g., ROUGE), and relevance scoring (e.g., answer relevance, faithfulness).
Since human qualitative assessments can be costly and time-consuming, alternative approaches are often used. One common method is to leverage another LLM or model to perform the evaluation, effectively using an “LLM as a judge” to assess the output, making the evaluation process more scalable.
- Test result reporting
Create a standardized reporting and analytics framework to track KPIs across multiple agent evaluation runs. Test results, while they may be summarized as PASS or FAIL, should also provide detailed insights for each individual task. This includes assigning specific task-related scores and offering clear explanations for why a particular score was given. This ensures transparency and helps in understanding the agent’s strengths and areas for improvement, fostering more informed decision-making.
- Test execution
The use of qualitative metrics and other LLMs isn’t always foolproof. While a test result may be reported as PASS or FAIL, it should undergo a critical Human Evaluation stage. An LLM scoring a test result as low or high serves as a helpful input but shouldn’t be the final determination of the outcome. Human evaluation remains essential for certifying test results and ensuring the reliability of agent performance.
The evaluation framework should be continuously refined based on insights from production. It is important to ensure that test cases are representative of real-world deployment scenarios. As new challenges or opportunities arise, update and add test cases that were not originally considered in the planning phase. This ongoing adaptation will help maintain the relevance and robustness of the testing process.
Agent deployment
Agent deployment combines the best practices from model deployment in classical LLMs, as well as software applications and data engineering pipelines. Like these fields, there isn’t a one-size-fits-all approach for deploying agents. Common practices include using containers and CI/CD (Continuous Integration/Continuous Deployment) setups to streamline updates and management.
Agents may use object storage as a persistence layer to store various forms of knowledge, long-term memory, and vector database artifacts. Alternatively, agents can be deployed directly inside databases, for example, as native applications using Snowflake’s Snowpark Container Service. This approach allows agents to benefit from the database’s built-in access control, dynamic scaling, and load-balancing capabilities during runtime, ensuring efficient and secure operation.
Agent monitoring and observability
Without proper oversight, AI agents can become unpredictable, inefficient, or even harmful to organizational processes. It’s essential to implement robust checkpoints to mitigate risks, maintain compliance with internal policies, and ensure ethical AI deployment. This involves not just tracking what agents do, but understanding how they make decisions and interact with various systems. Clear escalation protocols must be in place to allow immediate human intervention when agents encounter scenarios beyond their capabilities or display potentially risky behavior.
Traditional observability tools focus on basic metrics, offering predictive maintenance and behavioral pattern recognition. AI agent monitoring, however, adds a layer of context-aware observability, allowing teams to monitor more intricate aspects of agent performance. Leading observability providers and cloud services are integrating AI agent monitoring features, alongside a new wave of specialized vendors.
Common metrics for monitoring AI agents include tracking input (prompt) and output (completion) tokens, as well as identifying trends in token consumption over time to assess agent efficiency and performance.
5. AI Agent System Architecture
The task-oriented architecture of agentic systems decomposes complex tasks into smaller, manageable subtasks, improving functionality isolation, reducing complexity, and enhancing both maintainability and incident response times. Subtasks can be executed in parallel, allowing for independent scaling and more efficient resource allocation. They are also reusable, facilitating the creation of new functionalities by combining them, and can share components such as prompts and logic.
Figure 6 illustrates the architecture of an agentic system, demonstrating its modular and scalable design.
Key components of the agent architecture include:
- User interface
The UI enables agents to perceive and interact with their environment through voice commands or text input via a Natural Language Interface (NLI). The agent should be capable of understanding and responding to natural language queries, including complex requests and follow-up questions. The interface should dynamically adapt to the user’s preferences and skill level while safeguarding the security and privacy of user data. In addition to text and voice inputs, the user interface may incorporate sensors such as cameras or microphones.
In a multi-agent environment, the user interface should also be able to capture inputs from other agents. It’s crucial that agents provide transparency regarding their reasoning and decision-making processes. This includes delivering clear error messages and offering suggestions for improvements when needed.
The UI interfaces with a task orchestrator/controller, which is made up of two key components: Task planner and Plan executor.
- Task planner
The task planner breaks down complex objectives into granular, actionable steps and sequences tasks according to dependencies, resource availability, and deadlines. It calls upon the appropriate LLM, located within the shared resource layer (as shown in Figure 6), to apply logical reasoning to optimize task sequencing.
The planner identifies potential challenges and suggests alternative approaches, adapting plans based on real-time feedback, environmental changes, or resource constraints. Acting as a workflow orchestrator, the task planner ensures seamless coordination between various agent components and triggers the appropriate actions at each stage of the process.
- Plan Executor
The execution of subtasks within a tightly orchestrated workflow involves advanced techniques like prompt engineering, chain-of-thought reasoning, few-shot learning, RAG, and function-call interfaces. The plan executor may trigger external actions by making API calls or invoking Python functions.
While typical AI workloads, such as RAG, are stateless and atomic, an agentic architecture requires the maintenance of state. Memory has become a critical component in this context, as agents need to retain environmental state, user preferences, and historical execution data. This memory may be either episodic or infinite, depending on the agent’s requirements.
Each action in the workflow is treated as a stateful transaction, complete with rollback and error propagation mechanisms. Agents must ensure transactional integrity while adhering to security and compliance guidelines, guaranteeing that all processes are executed in a secure and reliable manner.
- Verification
Using judgment and reflection, agents autonomously adapt to changing circumstances, enabling them to make decisions that align with evolving situations. In cases where an agent encounters challenges beyond its capabilities, it should be designed to escalate the issue for human intervention. This ensures that the system remains reliable and responsive to real-world complexities.
Feedback loops are critical for continuous improvement, as agents learn from the outcomes of their interactions and refine their performance over time. These loops also enable the system to optimize future decision-making processes, making it more effective in delivering desired outcomes. Additionally, the verification loop serves as an essential safeguard, ensuring that responses meet ethical standards and do not deviate from established guidelines. This loop helps mitigate risks and maintain the integrity of agent behavior in dynamic environments.
- Shared resource layer (memory)
This layer encompasses essential tools such as LLM providers and memory management. Short-term memory helps track task execution or conversation flow within a specific thread or session, ensuring context is maintained during interactions. Long-term memory, on the other hand, allows agents to retain information across multiple sessions, enabling them to recall past interactions, user preferences, and accumulated knowledge over time.
Semantic memory stores learned facts or knowledge relevant to specific tasks or interactions, allowing the agent to reference previously acquired information to improve responses. This capability is crucial for enhancing task accuracy and personalization.
Episodic memory, akin to human memory, enables agents to remember specific events or interactions. This type of memory is valuable when a user seeks to revisit past conversations or episodes, allowing the agent to recall details from previous exchanges on a given topic, enhancing the continuity and relevance of future interactions.
Depending on the type of AI agent (as discussed in question #2), the concepts shared here can manifest in various forms. Iterating between reasoning and action, or reflecting on past performance, can help refine responses and improve future outputs. Common techniques for iterative reasoning include:
- ReAct (Reason-Act)
ReAct integrates reasoning and action in a continuous loop, combining thought generation and decision-making into one process. This method allows agents to iteratively generate reasoning steps and take corresponding actions. While it’s useful for exploring open-ended problems, it doesn’t guarantee a definitive output or repeatable experiences.
- Reflexion
This technique introduces self-reflection, where the model can adjust its responses based on feedback. It typically involves revisiting previous steps, correcting errors, or refining reasoning to enhance the solution. The feedback loop helps the model learn from past decisions, improving its responses over time.
- LLM Modulo Framework
The LLM Modulo Framework uses large language models (LLMs) as plan generators but relies on an external critique loop for validation and feedback. The framework’s effectiveness and repeatability depend on the scope and quality of the external critique loop, which is customized according to the specific use case.
These techniques enhance the iterative and adaptive nature of AI agents, allowing them to refine their processes and deliver more accurate, context-aware results.
6. AI Agent Framework
In the Agent System Architecture, as illustrated in Figure 6, tasks are decomposed into multiple subtasks that leverage the shared resource layer for tools, LLMs, and memory. This modular approach enables efficient execution, real-time reflection, and dynamic adaptation to changing environmental conditions. The primary objective of an agent framework is to abstract the complex underlying processes, allowing developers to focus on addressing core business problems without getting overwhelmed by technical intricacies.
To provide an optimal developer experience, an agent framework should offer:
- Low-code development tools as well as pro-code SDKs to enable easy building, testing, and experimentation.
- Templates and customization options to handle domain-specific business logic and task orchestration efficiently.
- Connectors and integrations with various services to seamlessly execute specific functions and workflows.
- Enterprise-grade features such as governance, security, and observability to ensure compliance and track agent performance.
This topic deserves a dedicated deep dive, so we’ll keep our discussion concise here. Additionally, the landscape of agent frameworks is evolving rapidly, with a proliferation of vendors offering solutions that range from proprietary systems to open-source platforms. Given the dynamic nature of this space, significant consolidation is likely in the near future.
In this FAQ, we highlight a selection of representative agent frameworks, listed in alphabetical order to ensure neutrality and inclusivity of options.
- Amazon Bedrock Agents is tightly integrated with its models as well as Knowledge Base data sources.
- Crew.ai was built as an open-source offering and is used widely. It offers real-time orchestration of multiple AI agents. Developers can develop agents in Crew.ai and deploy them in partner platforms like IBM’s watsonx.
- Google Cloud’s Vertex AI Agent Builder leverages Google’s foundation models and grounds agents in enterprise data. AI Agent Space is the vendor’s marketplace of agents built internally at Google and by its customers and partners. These agents can be customized or sold as SaaS
- IBM Bee Stack has most of the features one would expect from a framework and also allows agents to be created through a web browser. Its bee-code-interpreter runs a user or generated Python code in a sandboxed environment.
- LangChain’s LangGraph enables the creation of cyclical workflows, for iterative and recursive tasks. It is witnessing wide adoption.
- Microsoft AutoGen and Magnetic-One are both Python-based frameworks. The former is a more flexible and customizable framework, while the latter is a more specialized framework for building general-purpose AI agents. At Ignite 24, Copilot Studio showed access to 1800 models in Azure.
- Salesforce’s Agentforce launched at Dreamforce in September 2024 with 10,000 agents already built, many in the sales and marketing verticals. It leverages its Data Cloud foundation. It also has the Atlas Reasoning Engine to improve accuracy and reliability of the outcomes.
Numerous software vendors, such as H2O, SAP, and DataRobot, have introduced their own agent frameworks. This rapidly evolving landscape underscores the growing importance of AI agents in various industries. This list is by no means exhaustive and will be updated as many other vendors actively develop and release their frameworks.
7. Lessons Learned
Significant strides have been made in AI agent research over the past few months. However, many recent blogs and discussions suggest the looming threat of another “AI winter” or the need to double down on generative AI, particularly AI agents. If you’re feeling overwhelmed by the rapid pace and contradictory narratives surrounding generative AI, you’re not alone. The persistent reports of hallucinations in generative AI products are casting doubts on their reliability, and the widening gap between executive aspirations and the actual outcomes of generative AI use cases poses a significant challenge.
Drawing insights from initial experiences is critical in understanding the true scale of these challenges. Significant progress is still required across the entire AI agent workflow, including planning, reasoning, self-learning, and agent evaluation. These areas must evolve to close the gap between expectations and reality, paving the way for more reliable and effective AI agent deployment.
Figure 7 illustrates some of the top challenges faced when building and deploying AI agents.
- Planning
Perhaps the biggest challenge in deploying AI agents lies in selecting the right use case and target customer. When expectations are set too high, it can lead to disappointment and unrealized potential. Technically, use cases without clear task or process boundaries are not ideal for agentic architecture, as it thrives in structured, well-defined environments. Additionally, challenges such as a lack of intuitive user experience and low reliability at launch further complicate matters.
Given the inherent lower reliability of AI agents at the outset, organizations should focus on use cases where the tolerance for errors is more manageable, such as in research or exploratory tasks. Setting the right expectations around the accuracy and reliability of agents is crucial for ensuring that stakeholders understand the current limitations and potential benefits.
- Scope
AI agents have demonstrated success in certain areas, such as customer service and coding, but they are still in the early stages of development, making it challenging to scope and plan projects effectively. One key issue is that autonomous agents are not yet fully mature, making it difficult to accurately assess the necessary resources, timelines, and scope for their deployment.
The time required for testing, evaluating LLM outputs, and iterating is often longer than traditional software development processes. While agent development follows the general development paradigm of software engineering, testing and iteration more closely resemble the methodologies used in machine learning development. This distinction makes the development lifecycle for AI agents more complex and time-consuming than typical software projects.
- Technology
Technology challenges in the field of AI agents encompass several key areas: underdeveloped LLM reasoning, the lack of standardized agent evaluation benchmarks, and the nascent state of agent frameworks.
While large language models (LLMs) have made significant strides, much remains to be done to improve their reasoning capabilities. Traditionally, LLMs have advanced primarily through increased data and computational power. However, as we approach the limits of scaling laws, the focus must shift toward enhancing their reliability and reasoning.
Recently, there has been a surge in the development of powerful reasoning models, some of which are open-source or small enough to run on edge devices, offering hope for overcoming these limitations. These models may provide a path forward for better reasoning in AI agents.
Another challenge lies in the selection of agent frameworks. Many frameworks are chosen without a clear understanding of the specific needs of the use case. This can lead to the use of frameworks that are not ideal for production environments. Furthermore, there is a lack of standardized evaluation criteria for these frameworks, making it difficult to assess their suitability for experimentation or proof-of-concept (PoC) stages versus production deployment.
- Skills
AI engineering remains a developing field, and hiring skilled AI engineers who have hands-on experience building complex solutions like agents or Retrieval-Augmented Generation (RAG) models can be challenging. This lack of experienced talent can introduce uncertainty into the outcomes of projects from the start.
For organizations without in-house expertise, the decision-making process around whether to build, buy, or co-build solutions becomes crucial for driving successful project implementation. Balancing these options requires careful consideration of resource availability, long-term needs, and the potential for collaboration with external partners or vendors who bring specialized expertise.
- Value
The challenge of demonstrating clear value remains a significant hurdle, not only for AI agents but for the broader success of generative AI. While the cost of large language models (LLMs) has dropped significantly over the past two years — largely due to reductions in input and output token pricing — the overall pricing models remain opaque and vary widely across different platform vendors.
For example, Microsoft Copilot Studio has opted for a pricing model based on the number of messages exchanged, rather than token usage. This shift in pricing strategy reflects the ongoing evolution of cost structures for AI services, where the value proposition is still evolving and often difficult to quantify for both businesses and end-users. The inconsistency in pricing models across vendors adds to the uncertainty, making it harder for organizations to plan and budget for AI adoption effectively.
Considering these challenges, should organizations give up on their agentic adventures? While the decision ultimately rests with the business teams, it is worth noting that many of the current hurdles are likely to be resolved within the next 12 months. Organizations that lead the way in experimentation during this phase will be in the best position to capitalize on advancements as they emerge.
Wishing you all the best as you navigate your journey with agentic architecture!