What Have I Observed about Data Observability?
Ten Frequent Questions
- Why can’t my existing observability tool provide me with data observability?
- Why do I have to buy a tool? Can my data store or cloud vendors not build it?
- Why can’t I build it?
- How is data observability different from data quality?
- What should be the scope of data observability?
- How should I get started?
- When should I invest?
- How do I justify the cost?
- Who should be involved?
- What is the future direction of this space?
Data observability topic first came to my attention in early 2020, but I started covering this space in earnest only in September 2021. Over the last few months, this space has grown by leaps and bounds. My own research has sharpened into focus. I have spoken to many users, vendors and data professionals regarding this topic.
This document is my attempt to demystify and simplify the important space of data observability. The medium I have chosen to share my research is as frequently asked questions (FAQ). This format allows me to carve the topic into bite size nuggets that are easy to digest.
So, how did I prioritize key questions?
I am glad you asked. Many questions come up when I talk to prospective buyers. This is a compilation of the most common issues that represent the topics that potential consumers are grappling with. What this document is not is a definition or a primer on data observability. To learn more about data observability, please refer to these — What is Data Observability? and Data Observability Accelerates Modern Data Stack Adoption.
Most vendor pitches start with: let me tell you what I offer. This approach unfortunately doesn’t resonate well with the audience, who are still confused about why they should consider buying into this concept. Hence, this FAQ starts with ‘why’. As a result, you may find the order of questions unconventional.
So, without further ado, here are the questions.
Why can’t my existing observability tool provide me with data observability?
This is a common question that end users ask. They already have some observability or an application performance management (APM) tool in house and are confused why they need yet another tool. The insinuation in this question is whether they can wait long enough for Datadog, New Relic, Dynatrace, AppDynamics, Sumo Logic, LogicMonitor, etc. to deliver the additional capabilities that will complete the story.
Technically, there is no reason these companies can’t enter the space. However, the issue is about culture. Data professionals think of IT much differently than infrastructure and applications. Data has context, it needs to be modeled based on business concepts, rules and constraints and it can change frequently and unexpectedly. Take the example of a stateless application crash. The DevOps tool chain can restore it and operations can proceed as normal. However, if a database crashes, it needs to be recovered within a short time (RTO) and with no data loss (RPO) or it will be inconsistent or corrupt.
Within an organization, DevOps and data engineering are separate teams. Typically, observability tools are used by the former and data observability by the latter. DevOps have KPIs to ensure “infrastructure” is available, performant and at the most optimized cost. DevOps-inspired DataOps have KPIs to ensure “data” is securely stored, accessible, and is always reliable. The goals for both the teams are exactly the same — reliability. DevOps cares about the reliability of the infrastructure and DataOps for Data & Analytics requirements, followed by Machine Learning and AI applications.
It is conceivable that in the future these may merge. But for now, DevOps people don’t yet have the background or skills that are needed to build and conduct Data Engineering at scale, reliably. Hence, we feel these are reasons enough for you to consider data observability as a category separate from the overall observability space.
Why do I have to buy a tool? Can my data store or cloud vendors not build it?
Every vendor in the data and analytics stack knows acutely that they need to monitor and understand the state and health of their data landscape in their control. Hence, many use-case specific data tools and platforms are actively adding observability hooks. However, these solutions will not extend beyond their boundaries. For example, Snowflake doesn’t know how Fivetran, Apache Airflow or dbt transformed data. Some tools may be hosted by different cloud providers. So, what you get is a disjointed view of data, instead of end-to-end visibility into your entire data landscape.
This necessitates the need to procure an observability platform or cloud vendor neutral product that spans your entire pipeline. Now, most data observability vendors may not have integrations for all the technologies used in your stack, but check their roadmap to see when they will have a more complete coverage.
We feel that a third-party data observability tool will provide the most comprehensive option to handle end-to-end data pipeline needs. This future proofs you to handle future workloads that may need hybrid multi cloud deployments. It also helps in exploring decentralized or federated architectures, such as data mesh and data fabric.
Why can’t I build it?
Here we go again: build vs. buy. The real question is, what is your core intellectual property (IP)? If it is not developing software products, then one should consider buying a data observability tool that is continually evolving with the changes in the overall data and analytics stack.
The scope and sophistication of data observability keeps expanding. Developing these capabilities requires dedicated staff and in the long-term a significant undertaking.. If you are a technology company with a large IT department comprising thousands of engineers, like Apple or Meta, then it is possible for you to build a custom solution. However, if you are a bank or a healthcare provider, then building this capability will incur technical debt. IDC estimates that the cost to maintain apps is 4x the cost to build.
A common scenario is where organizations are actively looking to replace their home-grown solutions that were built before enterprise scale data observability tools came into the market. These organizations are hampered by the manual creation of rules and lack of scope and functionality. Modern tools keep adding advanced ML capabilities that learn patterns from the signals, optimize for seasonality, provide alerts and proactive recommendations. These tools also integrate with other metadata management products, such as catalogs.
Our recommendation is to evaluate existing data observability tools against your business requirements and consider building a tool only when you have highly specialized requirements. These external tools free up the staff from developing and maintaining internal operational capabilities, and instead focus their time on ensuring that they are building ROI from their data sets.
How is data observability different from data quality?
As data quality has been a persistent problem for decades, business leaders are looking for new and innovative ways to resolve this age-old problem. The stakes for dealing with low-quality data have increased tremendously in data-driven organizations that are increasingly dependent on predictive and prescriptive analytics. Best practices learnt from DevOps and site reliability engineering (SRE) are now being applied to data.
Data quality is a key capability of a comprehensive data observability product.
Static, rule-based, and reactive data quality monitoring (DQM) tools have existed for decades. They use data profiling techniques to generate static snapshots of data and metadata. However, data is constantly changing, requiring a more dynamic and scalable approach. Modern data observability tools continuously assess and detect anomalies, while teaching themselves new rules dynamically. They also expand the scope beyond simply technical metadata to business semantic layers and KPIs.
Just monitoring and alerting of anomalies is only one part of the story. The other part is how to make the outcomes actionable. In other words, how to detect and group similar alerts, triage and diagnose the problems and resolve them. Data stewards and engineers use the tool’s incident management workflow functionality to do root cause analysis and determine the next best action. Often data observability tools integrate with specialized data quality remediation tools.
Another question that arises is, can I just use a code base test option like open-source Great Expectations?
The key difference between a Data Observability tool and a testing framework is that the testing framework appears in the cycle of development of the data pipeline, and not after the pipeline is put into production. Code based tools allow developers to write assertions that test for changes in the codified rules. They require a heavy dose of Python coding, and hence appeal to developers. These tools primarily focus on testing, while observability adds constant, proactive monitoring, which they lack.
As you evaluate data observability products, understand how you will close the loop on data quality issues within your organization. However, data observability is more than just data quality. The next question addresses the full scope of data observability.
What should be the scope of data observability?
Data observability tools have steadily increased functionality to address growing customer requests. As almost all the tools in this space are new, the vendors are evolving their products rapidly. For example, finops is now increasing a focus area, given cloud costs are coming into question at large enterprises.
Because of this expansion of scope, we see data observability comprising two specializations:
- Data consumption-centered focused on data quality to resolve issues pertaining to data quality dimensions, such as missing values, duplicates, etc. and in the semantic layer.
- Data engineering-centered, which is concerned with the overall data engineering tracking the overall health and reliability of the data stack. It identifies and resolves anomalies in the data pipelines, underlying compute resources and cost pertaining to resource allocation and quality of data flowing through the pipelines.
The reason for splitting these two areas is because of their distinct characteristics, as the table below shows.
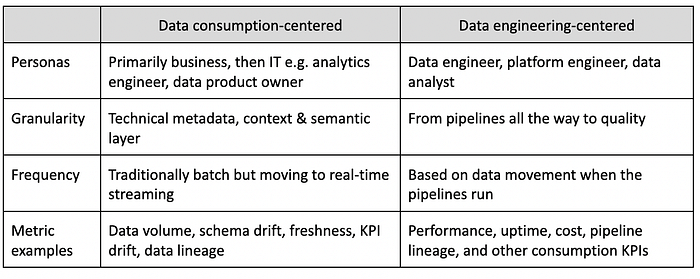
Our observation is that, in the early days of data observability, many best of breed players have emerged in each category, with the majority focused on data quality. As the industry matures, we will start seeing an emergence of category leaders who can deal with the complexity of technology and can produce IP to deal with observability demands of multiple layers.
While we are discussing the scope of data observability, two more questions often arise: how is this space different from application observability or application performance management (APM), and from infrastructure and operations observability (ITOps)? The answers to both these questions are in the Data Observability Evaluation Criteria document.
How should I get started?
Ok, now that I am convinced that I need a data observability tool, how do I get started? This issue is not just for data observability, but it crops up every time a new technology or approach emerges. We have observed that customers struggle with the last mile — deploying an observability solution effectively. They often ask for guidance, best practices, and pitfalls to avoid.
What we have seen work the best is to understand your business needs, assess the current state, and identify gaps. This is best achieved by building a maturity model that measures the effectiveness of current processes and establishes progressive improvements.
Although the concept of people, process and technology is trite, it works. Once you have baselined your maturity, shift your focus to the people and process side. We recommend creating a center of excellence (COE). The COE should have champions who advocate for data observability, create best practices, and guide the rest of the organization.
Finally, from the technical angle, document the gaps that are causing your architecture to be unstable before embarking on the data observability journey.
When should I invest?
A common question is, when in my digital transformation initiative should I invest in data observability products? We have seen that the answer varies depending upon the personas. The business and product teams are mostly interested in increasing the velocity of delivering new functionality.
Usually, the pain of not having observability is most acute with the technical teams. In our experience, if the data engineering team spends over 50% of its time handling operational issues, then formal observability and remediation processes are needed.
Data observability should also be considered when the data teams start growing rapidly. Typically, this happens when organizations have over ten people in their data teams and are considering distributed or decentralized approaches, like data mesh or data fabric.
We have frequently heard that data observability is not a must-have requirement. Our recommendation is to do a proof of concept (PoC) of the data observability tool and measure key metrics, such as time to detect and fix anomalies. If the pipeline is significantly more reliable, then a data observability tool should be deployed in production.
How do I justify the cost?
High-quality data and reliable pipelines lead to accurate and faster data-driven decisions, which leads to increased revenues. Businesses today rely on trusted data to perform advanced market/basket analysis, churn predictions, and plan marketing budget and strategies. In 2022, high-profile enterprise-level debacles because of incorrect ML models built on poor quality data include Zillow, Unity Technologies and Twitter.
We think that data observability is an essential part of the modern data stack and, hence, should garner the same attention to detail and considerations as any other component or the stack. But convincing the leadership team is not straightforward. Even when the IT leadership is convinced, observability projects may not be prioritized.
A common mistake is to start explaining capabilities of the tools. A better approach is to quantify the benefits of the tool and how its absence impacts the business. Start by estimating the total cost of down systems. The loaded term here is ‘total’ because it should include the impact on revenue, opportunity cost, and human labor cost to detect and remediate problems. A well-thought out analysis can demonstrate that the data observability tool is a small fraction of the cost saved to do:
- Increased revenue. Your data stack is balancing pressures from an increased number of users and workloads, demanding faster changes and increased complexity of the stack. It is easy to develop blind spots, where there is a lack of transparency into the data movement, i.e. lineage. Data observability can proactively guard against unexpected incidents, or remediate them quickly.
- Cost saving. Your IT staff should spend time on enhancing the functionality of the stack, and not on reacting to intractable issues in the complex pipeline. Observability should help right-size the infrastructure and provide a clear view onto cost overruns so that they can be optimized in a timely manner. Another benefit of observability is the reduction in time to deploy new capabilities for the business.
- Risk reduction. Impact of poor data quality and infrastructure failures leads to compliance issues and reputation. Observability can reduce these impacts.
Ask your data observability vendor to provide calculators to help estimate the cost of the tool.
Who should be involved?
Data observability directly and indirectly affects many roles within an organization. While business is the ultimate beneficiary, the role that directly benefits the most from data observability is the data engineer. As this role is in high demand and in short supply, a data observability tool can be used to alleviate bottlenecks.
Data consumption-centered data observability aims to help data owners quickly identify data quality problems in the source systems and not when the data has landed into a downstream system, such as a data warehouse. This shift-left approach reduces the cost for data remediation. In many organizations, it is still the data engineer who is involved in data quality tasks.
Data engineering-centered data observability aims to help the operations staff (DataOps) and data engineers ensure reliability of the pipelines. Many organizations run thousands of pipelines daily. Hence, the operations team needs to have automation built-in to detect anomalies and initiate tasks to remediate issues.
What is the future direction of Data Observability?
We have observed an enormous growth of startups that mimics the growth of the thriving overall observability space with many successful offerings. If we were to extrapolate from the rapid growth of the cloud data platforms in recent years, then we expect that the data observability space will continue to grow, and will have multiple successful companies.
90% of data and analytics budgets are being spent on data management tasks, like data catalogs, dataops and cost optimization. If the cloud data warehouse market is at $250B, and data observability is just 5% of that market, it makes the space worth $12B.
We expect all major cloud providers and data platform providers will enter this space. However, there will still be a need for cross platform, cross cloud and on-premises tools. These are still early days for data observability, but it is already establishing its presence on the strength of helping companies improve the reliability of their data stack.
Summary
Data is transformative. But to truly benefit from it, one needs to understand its context, its signals, embedded relationships, patterns, and its metrics. The problem is that these are often hidden in plain sight. What is needed is a tool that can glean this information and deliver intelligence that makes our data stacks reliable. That is the mission of data observability.
Like every new product category, organizations are grappling with the data observability space. This document captures some of the most common questions and provides recommendations on how to navigate the early phase of this space.
